Part 1: Training
- Download the latest build of RVC-Beta from lj1995/VoiceConversionWebUI on huggingface.co. At the time of writing, this is the latest build: https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/RVC-beta-20230513.7z The file is 3GB because it comes with a fully set up Python environment with pytorch and a bunch of other dependencies installed. pytorch alone is like 2.5 GB. This is required for training & running the neural net.
- Create a directory (rvc-beta) and expand that archive inside that directory. This is what that directory should looks like:
- Double click go-web.bat. This will start a webserver that you can access by typing localhost:7897 (or whatever port is printed out in the little window that appears).
- Prepare training data. I used yt-dlp to download some vods of a vtuber, isolated the audio using ffmpeg, and split it up into 10-minute chunks. I picked the chunks with the best audio quality (no background noise, no other speakers) and put those into D:\rvc-beta\training
this is how I got my training data using a wsl shell:
$ git clone https://github.com/yt-dlp/yt-dlp
$ cd yt-dlp
$ python3 -m pip install -r requirements.txt
# -N 128 tells yt-dlp to use 128 connections to download chunks of the video in parallel, resulting in a much faster download than using a single connection
$ python3 ./yt_dlp/__main__.py -N 128 https://www.youtube.com/watch?v=TbEe5OLxeMo
$ mv '[05⧸03⧸2023] Veibae - Ocarina of Time [Part 4] [TbEe5OLxeMo].webm' veibae_oot_part_4.webm
# Extract & compress audio
$ ffmpeg -i veibae_oot_part_4.webm -b:a 192k veibae_oot_part_4.mp3
# Split into 10-minute chunks.
$ ffmpeg -i veibae_oot_part_4.mp3 -f segment -segment_time 600 -c copy veibae_oot_part_4_%03d.mp3
# Put all high-quality (one speaker, no background noise) chunks into a directory
$ mkdir -p /mnt/d/rvc-beta/training_data/veibae
$ mv veibae_oot_part_4_00[12345].mp3 /mnt/d/rvc-beta/training_data/veibae/
# Delete unused data to free up disk space
$ rm -f *.webm *.mp3
After doing the stuff above, I have a directory with a bunch of 10-minute mp3 files containing high-quality training data. In my case, it's at D:\rvc-beta\training_data\veibae. We'll need this path in a minute.
- Train the model. Open your web browser and go to localhost:7987 (enter that in the same way you'd enter a URL). If a webpage doesn't load, make sure you completed step 3.
- Go to the Train tab.
- Put veibae (or the name of the voice you're making) as the Input experiment name.
- Leave target sample rate at 40k.
- Set pitch guidance to false unless your training data is exclusively singing.
- Put the path where your training data is located in the Input training folder path. In my case it's at D:\rvc-beta\training_data\veibae.
- Set Save frequency to 20.
- Set total_epochs to 160.
- Set batch_size to 40. If you run out of VRAM, divide the number by 2 until training starts working.
- Hit One-click training and keep an eye on the console.
Expect training to take at least 1 hour to complete. It can vary wildly depending on your hardware, how much training data you're using, your batch_size, and how many epochs you're using.
This is about what the training page should look like. I'm using many more epochs since I'm using 4 hours of data in this test. You can adjust the amount of training data & epochs but (1 hour of data + 160 epochs) gave me significantly better results than either (10 minutes + 160 epochs) or (1 hour + 20 epochs). 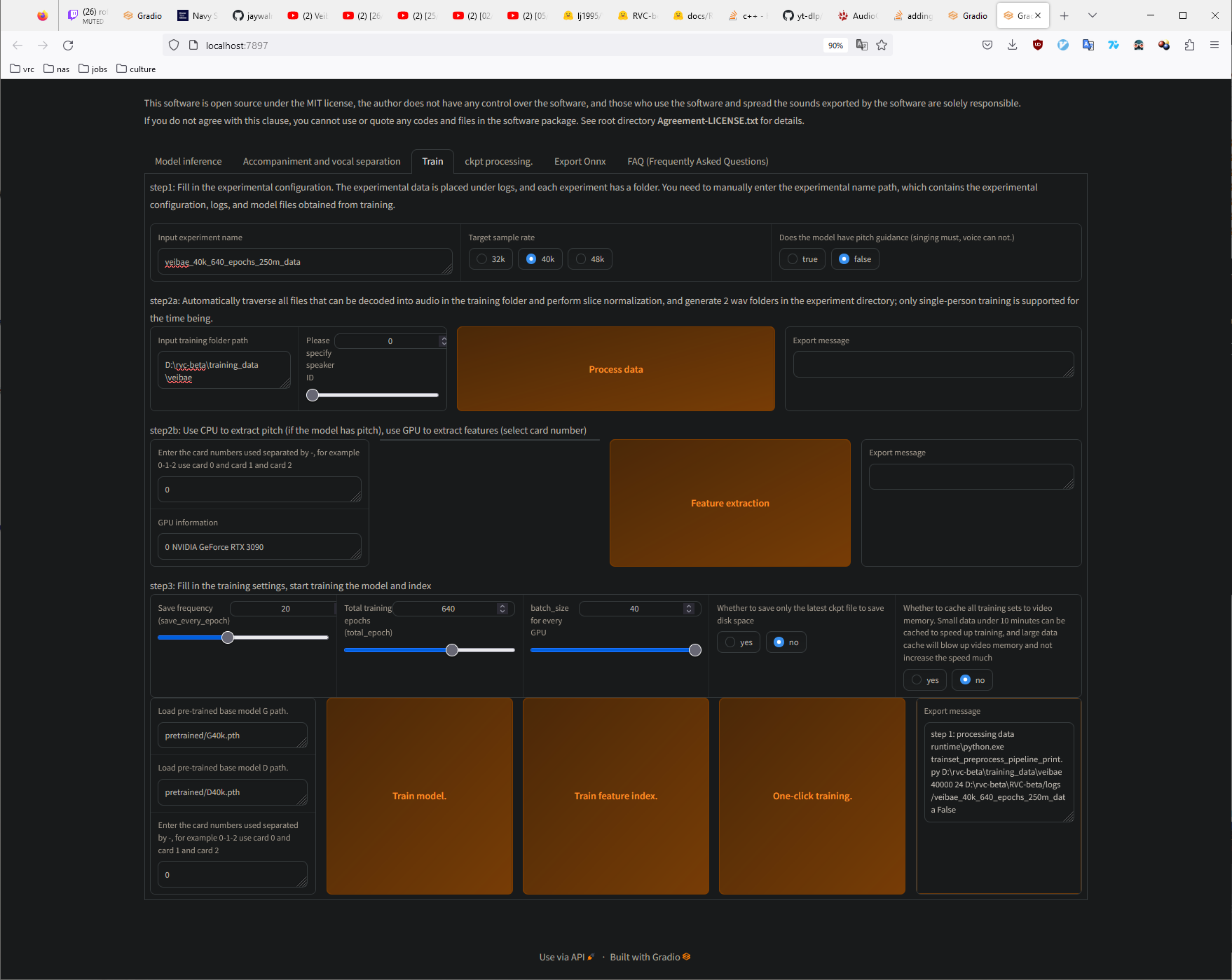
This is what my training data folder looks like in the above run. Each file is 10 minutes of voice audio. 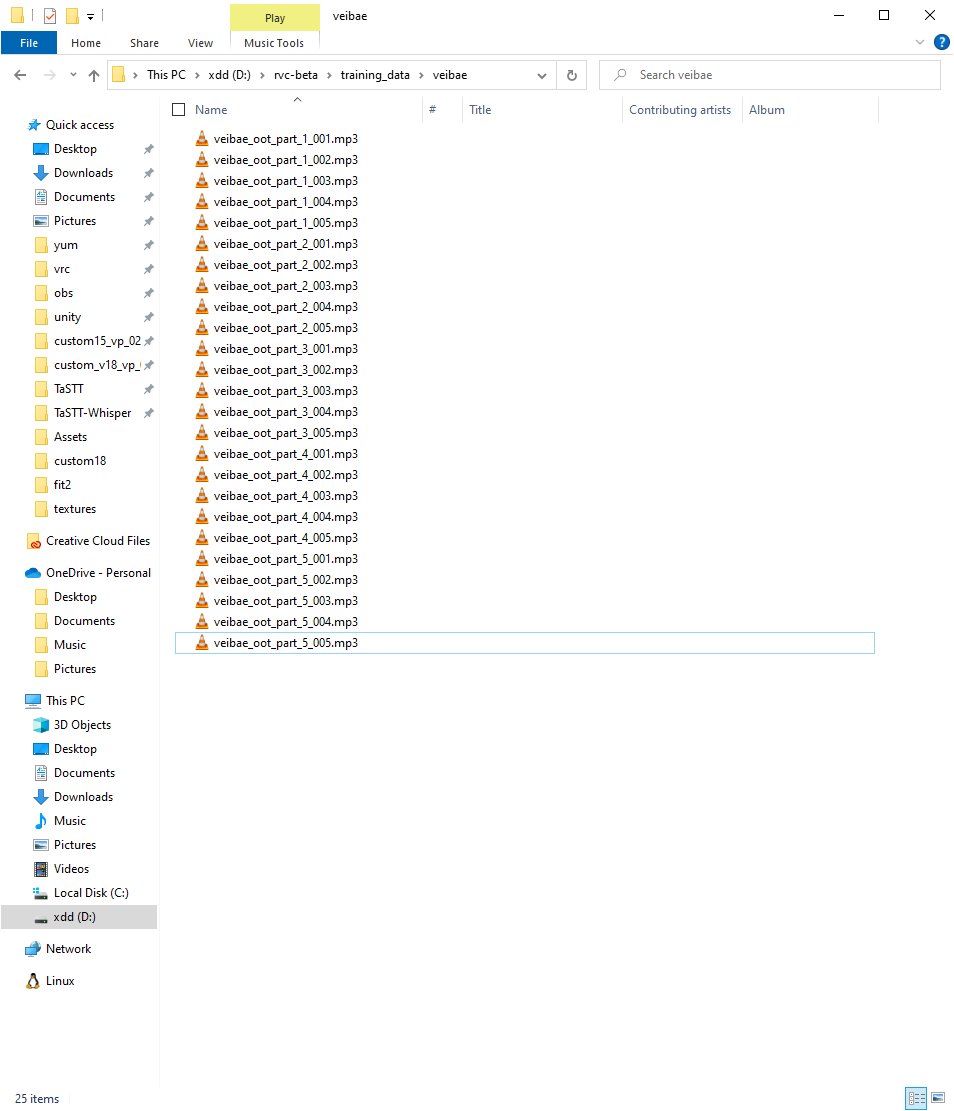
Training with batch_size=40 is a little VRAM-hungry